
数据页面布局
本章提供一个 Redrock Postgres 的表和索引所使用的页面格式的概述。序列和 TOAST 表的格式就像一个普通表一样。实际上,表和索引访问模式并不需要使用这种页面格式。heap表访问方法总是采用这种格式。目前所有的索引方法的确也使用这个基本格式,但索引元页里的数据通常并不遵循项布局规则。
在下面解释中,一个字节被假定包含 8 个位。另外,术语 item 指的是存储在一个页面里的独立数据值。在一个表里,一个项是一个行;在一个索引里,一个项是一条索引记录。
每个表和索引都以一个固定尺寸(通常是 8 kB,不过在编译服务器时可以选择其他不同的尺寸)的页面数组存储。在表中,所有页面在逻辑上都相同,所以一个特定的项(行)可以被存储在任何页面里。在索引里,第一个页面通常保留为元页来保存控制信息,并且依索引访问方法的不同,在索引里可能有不同类型的页面。
表 1 显示一个页面的总体布局。每个页面有六个部分。
表 1. 总体页面布局
| 项 | 描述 |
|---|---|
| PageHeaderData | 40 字节长。包含关于页面的一般信息,包括空闲空间指针。 |
| ItemXactData | 数据项相关的事务状态数据数组。每一个事务状态数据条目 24 字节。 |
| ItemIdData | 指向实际项的项标识符数组。每一个条目是一对(偏移量、长度)。每个项 4 字节。 |
| Free Space | 未分配的空间(空闲空间)。新项标识符从这个区域的开头开始分配,新项从其结尾开始分配。 |
| Items | 实际的项本身。 |
| Special Space | 索引访问模式相关的数据。不同的索引访问方式存放不同的数据。在普通表中为空。 |
每个页面的头 40 个字节组成页头(PageHeaderData)。它的格式在表 2 里详细介绍。第一个域跟踪此页面最近被修改的时间戳。第二个域包含该页面的校验码(如果data checksums被启用)。页面头中接下来的 1 字节(pd_version)存储一个版本指示器。Redrock Postgres 2 使用版本号 1;更早的版本使用版本号 0(基本页面布局和头格式在大部分这些版本里都没有改变,但是堆的行头部布局有所变化)。接下来一个1字节的域包含标志位。此后跟随着 4 个 2 字节长度的整数域(pd_trans、pd_lower、pd_upper和pd_special)。这些域包含从页面开始位置到项标识符开头的字节偏移、到未分配空间开头的字节偏移、到未分配空间结尾的字节偏移以及到特殊空间开头的字节偏移。最后的域是一个提示,它显示清理该页是否可能获益:它跟踪在页面上最老的可清理行的删除时间戳。
表 2. PageHeaderData布局
| 域 | 类型 | 长度 | 描述 |
|---|---|---|---|
| pd_time | LogicalTime | 8 字节 | 最后修改这个页面的逻辑时间戳 |
| pd_checksum | uint16 | 2 字节 | 页面校验码 |
| pd_fsc | uint16 | 2 字节 | 页面中的碎片空闲空间 |
| pd_version | uint8 | 1 字节 | 页面布局版本号信息 |
| pd_flags | uint8 | 1 字节 | 标志位 |
| pd_type | uint8 | 1 字节 | 页面类型 |
| pd_sqn | uint8 | 1 字节 | 页面修改序列号 |
| pd_trans | LocationIndex | 2 字节 | 到项标识符开头的偏移量 |
| pd_lower | LocationIndex | 2 字节 | 到空闲空间开头的偏移量 |
| pd_upper | LocationIndex | 2 字节 | 到空闲空间结尾的偏移量 |
| pd_special | LocationIndex | 2 字节 | 到特殊空间开头的偏移量 |
| pd_prune_time | LogicalTime | 8 字节 | 页面上最老的可清理行的删除时间戳,如果没有则为0 |
| pd_csc | LogicalTime | 8 字节 | 最后清理这个页面的逻辑时间戳 |
在页头后面是项标识符(ItemIdData),每个占用四个字节。一个项标识符包含一个到项开头的字节偏移量(它的长度以字节计),以及一些属性位,这些属性位影响对它的解释。新的项标识符根据需要从未分配空间的开头分配。项标识符的数目可以通过查看pd_lower来判断,在分配新标识符的时候pd_lower会增长。因为一个项标识符在被释放前绝对不会移动,所以它的索引可以用于长期地引用一个项,即使该项本身因为压缩空闲空间在页面内部进行了移动。实际上,PostgreSQL 创建的每个指向项的指针(ItemPointer,也叫做CTID)都由一个页号和一个项标识符的索引组成。
项本身存储在从未分配空间末尾开始从后向前分配的空间里。它们的实际结构取决于表包含的内容。表和序列都使用一种叫做HeapTupleHeaderData的结构,如下文所述。
最后一部分是“特殊部分”,它可以包含访问方法想存放的任何东西。比如,b-tree 索引用它存储指向页面的左右兄妹的链接,以及其他一些和索引结构相关的数据。普通表并不使用这个部分(通过设置pd_special等于页面大小来表示)。
图 1 举例说明这些组件如何在一个页面中布局。
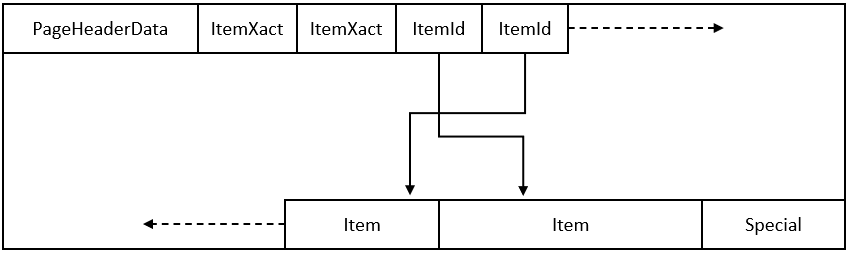
表 3 列出并描述了实际数据项引用的每个事务项,这些事务项在大多数计算机上占用 24 字节。
表 3. ItemXactData 布局
| 域 | 类型 | 长度 | 描述 |
|---|---|---|---|
| xid | TransactionId | 8 字节 | 修改了此块的最近事务的事务 ID。格式为(回滚段号,事务槽号,序列号)。 |
| uba | ULogRecPtr | 8 字节 | 此事务为该数据块产生的最新撤消记录的撤消记录地址,包括块序列号。格式为(块号,块序列号,记录项索引)。 |
| info | uint32 | 4 字节 | 如果事务尚未清理,高位 2 字节的 12 位用来表示此事务拥有的碎片空闲空间额度。高位 2 字节的 4 位用来标识此事务的状态。事务清理完毕后,用来表示事务提交逻辑时间戳的高位 4 字节部分,高位 2 字节的 4 位事务状态位被标记为已被清理。 |
| bas | uint32 | 4 字节 | 事务提交后,事务提交逻辑时间戳的基础部分。 |
数据块一开始会包含两个初始事务项 - 这是在 Redrock Postgres 中创建表或索引时的默认值。如果想要创建(或重建)一个数据库对象让每个数据块具有更多事务项,从而可以避免在更高级别的并发修改中发生争用,可以通过在对象创建时设置 initrans 存储参数来实现。不过在需要的时候,任何块中的事务项数组都可以动态增长,只要块中还有足够的可用空间。
事务项的存在是为了标识最近更改数据块的事务,但是标识事务的信息需要占用额外的空间,Redrock Postgres 倾向使事务项的数组尽可能短。此外,在索引叶块分裂时,原来叶块上的事务项会被复制到新的叶块中。
所有表行都用同样方法构造。它们有一个定长的头部(在大多数机器上占据 8 个字节),后面跟着一个可选的空值位图以及用户数据。 该头部在表 4 里详细描述。实际的用户数据(行的列)从t_hoff指示的偏移位置开始,它必须总是该平台的 MAXALIGN 距离的倍数。空值位图只有在t_flags中的 HEAP_HASNULL 位被设置时存在。如果存在,那么它紧跟在定长的头部后面,并占据足够的字节来容纳每个数据列对应的一个位(也就是说,位数等于t_natts中的属性计数。)。在这个位的列表中,为 1 的位表示非空,而为 0 的位表示空。如果这个位图不存在,那么所有列都被假设为非空的。如果需要对齐t_hoff使之成为 MAXALIGN 的倍数,那么填充将出现在空值位图和用户数据之间(这样也保证了用户数据得到恰当的对齐)。
表 4. HeapTupleHeaderData 布局
| 域 | 类型 | 长度 | 描述 |
|---|---|---|---|
| t_time | uint32 | 4 字节 | 修改事务未被清理前,标识插入或删除的命令 ID;被清理后标识事务提交时间戳 |
| t_lock | uint8 | 1 字节 | 指向修改事务的事务项 |
| t_flags | uint8 | 1 字节 | 一些属性,加上多个标志位 |
| t_natts | uint8 | 1 字节 | 列的数目,超出 255 个列以后,会将高位的列数目放在 t_hoff 里面 |
| t_hoff | uint8 | 1 字节 | 到用户数据的偏移量;几个低位用于表示列的数目 |
只有从其他表里获取了信息之后才能解释实际的数据,这些信息大多数在pg_attribute中。标识域位置的关键值是attlen和attalign。我们没有办法直接获取某个特定属性,除非它们是定宽并且没有空值。所有这些复杂的操作都封装在函数 heap_getattr、fastgetattr 和 heap_getsysattr 中。
要读取数据的话,你需要轮流检查每个属性。首先根据空值位图检查该域是否为 NULL。如果是,那么跳到下一个。然后保证你的对齐是正确的。如果域是一个定宽域,那么所有字节都简单地放在其中。如果它是一个变长域(attlen = -1),那么它就会有点复杂。所有变长数据类型都使用一个通用的头部结构struct varlena,它包含所存储的值的总长度以及一些标志位。根据标志的不同,数据可能在线内或者是在一个 TOAST 中,还可能是压缩的(参阅第 68.2 节)。