
Data Page Layout
This section provides an overview of the page format used within Redrock Postgres tables and indexes. Sequences and TOAST tables are formatted just like a regular table. Actually, use of this page format is not required for either table or index access methods. The heap table access method always uses this format. All the existing index methods also use the basic format, but the data kept on index metapages usually doesn’t follow the item layout rules.
In the following explanation, a byte is assumed to contain 8 bits. In addition, the term item refers to an individual data value that is stored on a page. In a table, an item is a row; in an index, an item is an index entry.
Every table and index is stored as an array of pages of a fixed size (usually 8 kB, although a different page size can be selected when compiling the server). In a table, all the pages are logically equivalent, so a particular item (row) can be stored in any page. In indexes, the first page is generally reserved as a metapage holding control information, and there can be different types of pages within the index, depending on the index access method.
Table 1 shows the overall layout of a page. There are six parts to each page.
Table 1. Overall Page Layout
| Item | Description |
|---|---|
| PageHeaderData | 40 bytes long. Contains general information about the page, including free space pointers. |
| ItemXactData | Array of transaction items referenced by the actual items. 24 bytes per item. |
| ItemIdData | Array of item identifiers pointing to the actual items. Each entry is an (offset,length) pair. 4 bytes per item. |
| Free Space | The unallocated space. New item identifiers are allocated from the start of this area, new items from the end. |
| Items | The actual items themselves. |
| Special Space | Index access method specific data. Different methods store different data. Empty in ordinary tables. |
The first 40 bytes of each page consists of a page header (PageHeaderData). Its format is detailed in Table 2. The first field tracks the timestamp of the most recent modification of this page. The second field contains the page checksum if data checksums are enabled. The next 1 byte of the page header, pd_version, store a version indicator. Redrock Postgres 12 used version number 1; prior releases used version number 0. (The basic page layout and header format has not changed in most of these versions, but the layout of heap row headers has.) Next is a 1-byte field containing flag bits. This is followed by four 2-byte integer fields (pd_trans, pd_lower, pd_upper, and pd_special). These contain byte offsets from the page start to the start of item identifiers, to the start of unallocated space, to the end of unallocated space, and to the start of the special space. The page size is basically only present as a cross-check; there is no support for having more than one page size in an installation. The last field is a hint that shows whether pruning the page is likely to be profitable: it tracks the oldest logical time of unpruned deleted row on the page.
Table 2. PageHeaderData Layout
| Field | Type | Length | Description |
|---|---|---|---|
| pd_time | LogicalTime | 8 bytes | The time at which the block was changed |
| pd_checksum | uint16 | 2 bytes | Page checksum |
| pd_fsc | uint16 | 2 bytes | Fragmented free space in page |
| pd_version | uint8 | 1 byte | Page layout version number |
| pd_flags | uint8 | 1 byte | Flag bits |
| pd_type | uint8 | 1 byte | Page type |
| pd_sqn | uint8 | 1 byte | The change sequence number for last change to this page |
| pd_trans | LocationIndex | 2 bytes | Offset to start of item identifiers |
| pd_lower | LocationIndex | 2 bytes | Offset to start of free space |
| pd_upper | LocationIndex | 2 bytes | Offset to end of free space |
| pd_special | LocationIndex | 2 bytes | Offset to start of special space |
| pd_prune_time | LogicalTime | 8 bytes | Oldest logical time of unpruned deleted row on page, or zero if none |
| pd_csc | LogicalTime | 8 bytes | The time at which the last full cleanout was performed on the block. |
Following the page header are item identifiers (ItemIdData), each requiring four bytes. An item identifier contains a byte-offset to the start of an item, its length in bytes, and a few attribute bits which affect its interpretation. New item identifiers are allocated as needed from the beginning of the unallocated space. The number of item identifiers present can be determined by looking at pd_lower, which is increased to allocate a new identifier. Because an item identifier is never moved until it is freed, its index can be used on a long-term basis to reference an item, even when the item itself is moved around on the page to compact free space. In fact, every pointer to an item (ItemPointer, also known as CTID) created by PostgreSQL consists of a page number and the index of an item identifier.
The items themselves are stored in space allocated backwards from the end of unallocated space. The exact structure varies depending on what the table is to contain. Tables and sequences both use a structure named HeapTupleHeaderData, described below.
The final section is the “special section” which can contain anything the access method wishes to store. For example, b-tree indexes store links to the page’s left and right siblings, as well as some other data relevant to the index structure. Ordinary tables do not use a special section at all (indicated by setting pd_special to equal the page size).
Figure 1 illustrates how these parts are laid out in a page.
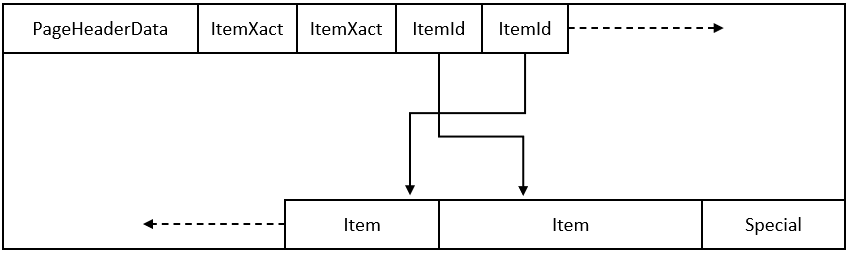
Table 3 lists and describes each transaction item referenced by the actual items, which occupied 24 bytes on most machines.
Table 3. ItemXactData Layout
| Field | Type | Length | Description |
|---|---|---|---|
| xid | TransactionId | 8 bytes | The transaction id of a recent transaction that has modified this block. The format is (undo segment, transaction slot number, sequence number). |
| uba | ULogRecPtr | 8 bytes | The undo record address—including the sequence (or incarnation) number—of the block of the most recent undo record generated by this transaction for this block. The format is absolute block address . block sequence number . record within block. |
| info | uint32 | 4 bytes | If the transaction has not been cleaned out, the 12 bits of high 2 byte means the free space credits owned by this transaction (if any). and the 4 bits of high 2 byte for this transaction state. After the transaction cleaned out, the time wrap part of the transaction, the 4 bits of high 2 byte would mark it cleaned out. |
| bas | uint32 | 4 bytes | After the transaction committed, the time base part of the transaction. |
A data block initially contains two transaction items—this is the default number when creating a table or index in Redrock Postgres. If you want to create (or rebuild) an object with more transaction items in each block, which you might do to avoid contention at higher levels of concurrent modification, you can do so by setting the initrans parameter at object creation time—but the array of transaction items in any block can grow dynamically if it needs to, provided there is enough free space available in the block.
The transaction items exist to identify transactions that recently changed a data block, but it takes space to identify a transaction, and Redrock Postgres likes to keep the array of transaction items as short as possible. Moreover, on an index leaf block split, the old transaction items is copied forward into the new leaf block.
All table rows are structured in the same way. There is a fixed-size header (occupying 8 bytes on most machines), followed by an optional null bitmap, and the user data. The header is detailed in Table 4. The actual user data (columns of the row) begins at the offset indicated by t_hoff, which must always be a multiple of the MAXALIGN distance for the platform. The null bitmap is only present if the HEAP_HASNULL bit is set in t_flags. If it is present it begins just after the fixed header and occupies enough bytes to have one bit per data column (that is, the number of bits that equals the attribute count in t_natts). In this list of bits, a 1 bit indicates not-null, a 0 bit is a null. When the bitmap is not present, all columns are assumed not-null. Any padding needed to make t_hoff a MAXALIGN multiple will appear between the null bitmap and the user data. (This in turn ensures that the user data is suitably aligned.)
Table 4. HeapTupleHeaderData Layout
| Field | Type | Length | Description |
|---|---|---|---|
| t_time | uint32 | 4 bytes | inserting or deleting command ID before the transaction cleaned out, or the transaction commit time after cleaned out. |
| t_lock | uint8 | 1 byte | Points to the transaction item that modified this row |
| t_flags | uint8 | 1 byte | number of attributes, plus various flag bits |
| t_natts | uint8 | 1 byte | The number of columns, after exceeding 255 columns, will put the high order bits of the number into t_hoff |
| t_hoff | uint8 | 1 byte | offset to user data; a few low order bits are used to indicate the number of columns |
Interpreting the actual data can only be done with information obtained from other tables, mostly pg_attribute. The key values needed to identify field locations are attlen and attalign. There is no way to directly get a particular attribute, except when there are only fixed width fields and no null values. All this trickery is wrapped up in the functions heap_getattr, fastgetattr and heap_getsysattr.
To read the data you need to examine each attribute in turn. First check whether the field is NULL according to the null bitmap. If it is, go to the next. Then make sure you have the right alignment. If the field is a fixed width field, then all the bytes are simply placed. If it’s a variable length field (attlen = -1) then it’s a bit more complicated. All variable-length data types share the common header structure struct varlena, which includes the total length of the stored value and some flag bits. Depending on the flags, the data can be either inline or in a TOAST table; it might be compressed, too (see Section 73.2).