
Network Storage Architecture
Redrock Postgres supports database servers running in storage server mode and can provide storage access services to other database servers connected to the network. We call these servers used to store and access data as database storage servers, and those servers that are mainly used for computing and processing data are called database computing servers. The computing server communicates with the storage server using the PostgreSQL frontend/backend protocol.
This section describes the storage architecture in network attached tablespaces.
In traditional local tablespaces, Write-Ahead Logging (WAL) is recorded when data pages are modified. WAL’s central concept is that changes to data files (where tables and indexes reside) must be written only after those changes have been logged, that is, after log records describing the changes have been flushed to permanent storage. If we follow this procedure, we do not need to flush data pages to disk on every transaction commit, because we know that in the event of a crash we will be able to recover the database using the log: any changes that have not been applied to the data pages can be redone from the log records. (This is roll-forward recovery, also known as REDO.) Transaction commit requires the log to be written, but the data page write may be deferred.
In network attached tablespaces, the main writes that cross the network are redo log records. No pages are likely written from database computing server, not for background writes, not for checkpointing, and not for cache eviction. Instead, the log applicator is pushed to database storage servers, where it can be used to apply redo log records and generate database pages in background, to implement data persistence.
Moving processing to a storage service also improves availability by minimizing crash recovery time and eliminates jitter caused by background processes such as checkpointing, background data page writing and backups.
Let’s examine crash recovery. In a traditional local tablespace, after a crash the system must start from the most recent checkpoint and replay the log to ensure that all persisted redo records have been applied. In network attached tablespaces, durable redo record application happens at the storage tier, continuously, asynchronously, and distributed across the fleet. As a result, the process of crash recovery is spread across all normal foreground processing. Nothing is required at database startup.
A core design tenet for database storage service is to minimize the latency of the foreground write request in database computing server. We move the majority of storage processing to the background. Given the natural variability between peak to average foreground requests from the storage tier, we have ample time to perform these tasks outside the foreground path.
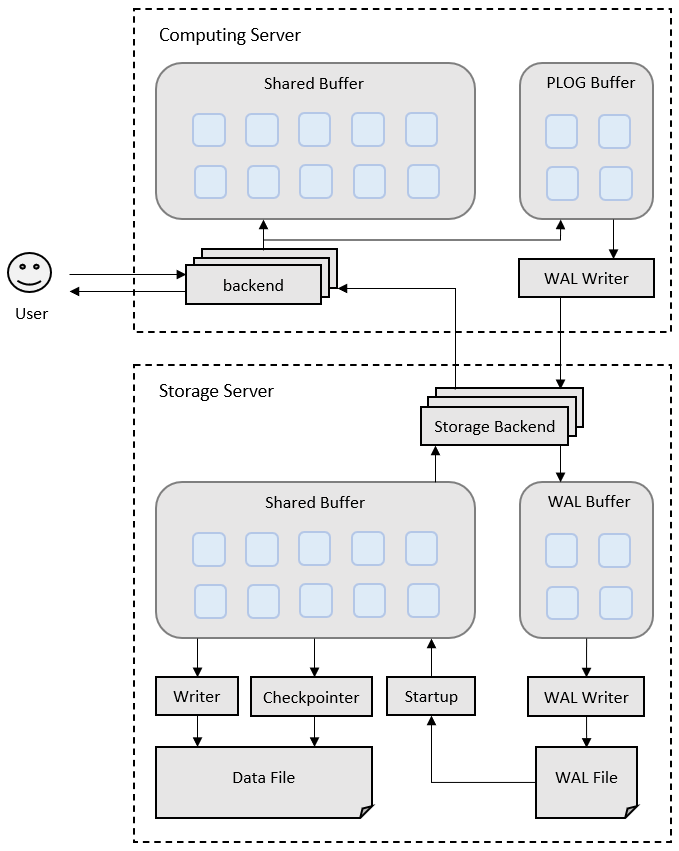
Let’s examine the various activities on the storage node in more detail. As seen in Figure 1, it involves the following steps:
-
Receive log record and add to WAL buffer area.
-
When a transaction in database computing servers is committed, it instructs the storage service to write the content in the WAL buffer to the disk and returns a confirmation message to notify the progress.
-
The startup process detects new log records and applies durable redo records continuously and asynchronously.
-
Database computing server receives the progress message returned by the storage service, when flushing dirty pages, it can determine whether the data page is persistent. If not, the computing server sends the data page to the storage service layer for persistence. (This does not happen unless the redo record application in storage service is too slow.)
-
Periodically perform checkpoint operations, flush all dirty data pages to the disk, and write a special checkpoint record to the WAL log file.
-
After a checkpoint, log segments preceding the one containing the redo record are no longer needed and can be recycled or removed.
Note that not only are each of the steps above asynchronous, only steps 1 and 2 are in the foreground path potentially impacting latency.
In network attached tablespaces, the database continuously interacts with the storage service and advance tablespace durability. When the database needs to write a dirty page to the storage tier, it is not necessary to really write the page after confirming that the reply from the storage service indicates that they have received the WAL log that records the page modification and that the log has been applied.
In network attached tablespaces, as with traditional local tablespaces, pages are served from the buffer cache and only result in a storage IO request if the page in question is not present in the cache.
If the buffer cache is full, the system finds a victim page to evict from the cache. In a traditional system, if the victim is a “dirty page” then it is flushed to disk before replacement. This is to ensure that a subsequent fetch of the page always results in the latest data. While in network attached tablespaces, database does not write out pages on eviction (or anywhere else), it enforces a similar guarantee: a page in the buffer cache must always be of the latest version.
Most traditional databases use a recovery protocol such as ARIES that depends on the presence of a write-ahead log (WAL) that can represent the precise contents of all committed transactions. These systems also periodically checkpoint the database to establish points of durability in a coarse-grained fashion by flushing dirty pages to disk and writing a checkpoint record to the log. On restart, any given page can either miss some committed data or contain uncommitted data. Therefore, on crash recovery the system processes the redo log records since the last checkpoint by using the log applicator to apply each log record to the relevant database page. This process brings the database pages to a consistent state at the point of failure after which the in-flight transactions during the crash can be rolled back by executing the relevant undo log records. Crash recovery can be an expensive operation. Reducing the checkpoint interval helps, but at the expense of interference with foreground transactions. No such tradeoff is required with network attached tablespaces.
A great simplifying principle of a traditional database is that the same redo log applicator is used in the forward processing path as well as on recovery where it operates synchronously and in the foreground while the database is offline. We rely on the same principle in network attached tablespaces as well, except that the redo log applicator is decoupled from the database and operates on storage nodes, in parallel, and all the time in the background. Once the database starts up it performs tablespace recovery in collaboration with the storage service and as a result, network attached tablespaces can recover very quickly (generally under 10 seconds) even if it crashed while processing over 10000 transactions per second.
The database still needs to perform undo recovery to unwind the operations of in-flight transactions at the time of the crash. However, undo recovery can happen when the database is online after the system builds the list of these in-flight transactions from the undo segments.