
Multitenant
Trust, or the lack thereof, is the number one factor blocking the adoption of software as a service (SaaS). A case could be made that data is the most important asset of any business—data about products, customers, employees, suppliers, and more. And data, of course, is at the heart of SaaS. SaaS applications provide customers with centralized, network based access to data with less overhead than is possible when using a locally installed application. But in order to take advantage of the benefits of SaaS, an organization must surrender a level of control over its own data, trusting the SaaS vendor to keep it safe and away from prying eyes.
To earn this trust, one of the highest priorities for a prospective SaaS architect is creating a SaaS data architecture that is both robust and secure enough to satisfy tenants or clients who are concerned about surrendering control of vital business data to a third party, while also being efficient and cost-effective to administer and maintain.
Every instance of a running PostgreSQL server manages one or more databases. Databases are therefore the topmost hierarchical level for organizing SQL objects (“database objects”). In an instance of Redrock Postgres, roles and tablespaces are database-level objects, each database has its own independent data architecture (including role, user, schema, and object permission information), and the data of each database is completely isolated.
Here’s an instance of Redrock Postgres, it has 3 template databases (template0, template1, and tenant_base) and 3 tenant databases.
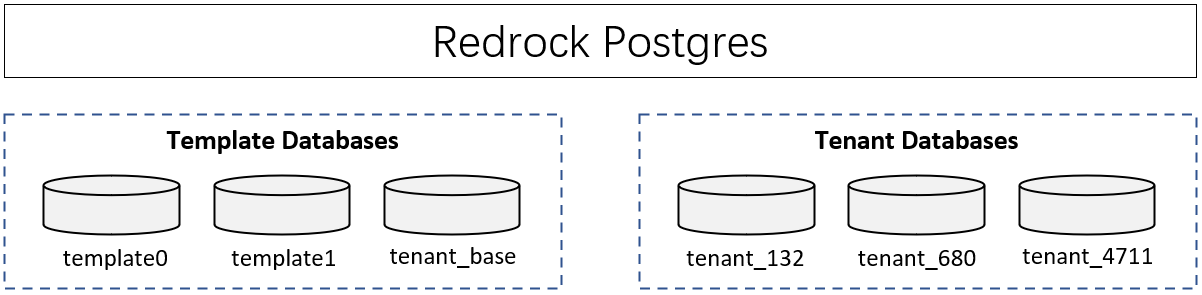
Computing resources and application code are generally shared between all the tenants on a server, but each tenant has its own set of data that remains logically isolated from data that belongs to all other tenants. Metadata associates each database with the correct tenant, and database security prevents any tenant from accidentally or maliciously accessing other tenants’ data.
Giving each tenant its own database makes it easy to extend the application’s data model to meet tenants’ individual needs, and restoring a tenant’s data from backups in the event of a failure is a relatively simple procedure. With the multi-tenant capabilities of Redrock Postgres, applications can easily implement SaaS mode deployments.
Many customers value data security. For example, customers in fields such as banking or medical records management often have very strong data isolation requirements, and may not even consider an application that does not supply each tenant with its own individual database.
CREATE DATABASE actually works by copying an existing database. By default, it copies the standard system database named template1. Thus that database is the “template” from which new databases are made. If you add objects to template1, these objects will be copied into subsequently created user databases. This behavior allows site-local modifications to the standard set of objects in databases. For example, if you install the procedural language PL/Scheme in template1, it will automatically be available in user databases without any extra action being taken when those databases are created.
There is a second standard system database named template0. This database contains the same data as the initial contents of template1, that is, only the standard objects predefined by your version of PostgreSQL. template0 should never be changed after the database cluster has been initialized. By instructing CREATE DATABASE to copy template0 instead of template1, you can create a “virgin” user database that contains none of the site-local additions in template1. This is particularly handy when restoring a pg_dump dump: the dump script should be restored in a virgin database to ensure that one recreates the correct contents of the dumped database, without conflicting with objects that might have been added to template1 later on.
Another common reason for copying template0 instead of template1 is that new encoding and locale settings can be specified when copying template0, whereas a copy of template1 must use the same settings it does. This is because template1 might contain encoding-specific or locale-specific data, while template0 is known not to.
To create a database by copying template0, use:
CREATE DATABASE dbname TEMPLATE template0;
from the SQL environment, or:
createdb -T template0 dbname
from the shell.
It is possible to create additional template databases, and indeed one can copy any database in a cluster by specifying its name as the template for CREATE DATABASE. It is important to understand, however, that this is not (yet) intended as a general-purpose “COPY DATABASE” facility. The principal limitation is that no other sessions can be connected to the source database while it is being copied. CREATE DATABASE will fail if any other connection exists when it starts; during the copy operation, new connections to the source database are prevented.
Two useful flags exist in pg_database for each database: the columns datistemplate and datallowconn. datistemplate can be set to indicate that a database is intended as a template for CREATE DATABASE. If this flag is set, the database can be cloned by any user with CREATEDB privileges; if it is not set, only superusers and the owner of the database can clone it. If datallowconn is false, then no new connections to that database will be allowed (but existing sessions are not terminated simply by setting the flag false). The template0 database is normally marked datallowconn = false to prevent its modification. Both template0 and template1 should always be marked with datistemplate = true.
template1andtemplate0do not have any special status beyond the fact that the nametemplate1is the default source database name forCREATE DATABASE. For example, one could droptemplate1and recreate it fromtemplate0without any ill effects. This course of action might be advisable if one has carelessly added a bunch of junk intemplate1. (To deletetemplate1, it must havepg_database.datistemplate = false.)The
postgresdatabase is also created when a database cluster is initialized. This database is meant as a default database for users and applications to connect to. It is simply a copy oftemplate1and can be dropped and recreated if necessary.
We can use a database as a management database, such as postgres. In the management database, create a table to store information about tenant databases.
CREATE TABLE IF NOT EXISTS tenant_database (
tenantname name,
dboid oid,
dbtemplate oid,
dbowner name,
dbapassword text
);
The tenant_database table contains the following columns:
| Name | Description |
|---|---|
tenantname |
Tenant name. |
dboid |
Object ID of the tenant database. |
dbtemplate |
Template from which the tenant database is made. |
dbowner |
Owner of the tenant database. |
dbapassword |
Password of the tenant database owner. |
When we create a new tenant database, modify and drop a tenant database, update the corresponding tenant database information in table tenant_database.